An amazingly simple solution for Mobile Apps to sync with the Cloud
Change Tracking API + JSON will make your dev life so easy you won’t believe it’s Azure SQL 06 Mar 2020
If you are creating a mobile app that will work sending data back and forth from the cloud (I guess that 99% of the apps fall into this use case), you will have at some point the need to sync data between the app and the cloud itself.
If you are a code-first person, grab it right away here:
This may be needed for several reasons, here’s a few:
- The app also offer a desktop or website experience and data can be managed from there too
- The app was not connected to the cloud for a while and some data processed in the cloud needs to be sent to the app
- A user freshly installed the app on a new device and of course now he/she want to see not only the new data but also the preexisting one
Let’s see the process a bit more in detail and let’s also generalize a bit so we can came up with a solution that will work on all possible situations.
An amazingly simple solution for Mobile Apps to sync with the Cloud using Change Tracking API
App to Cloud Sync
Synchronizing changes done on the app while it was offline is the easiest part. Figuring out what data has been created, changed or deleted in the application while it was offline is quite easy. Those changes are done directly from the application, so it has knowledge of them. You just need to make sure you keep track of those changes, for example put them in a queue, so that they can be sent to the cloud as soon the connectivity is back.
On a mobile device, you never know if connectivity will be available
There is nothing new here, as the concept of Connection Resiliency should be quite familiar to all mobile developers. On a mobile device, you never know if connectivity will be available or the endpoint you need to call will there to answer your requests. So you need to code defensively, making sure retry logic and requests queuing is something your application implements correctly. As I’m more experienced with C#, I’m aware of frameworks like Polly and resources like the following:
- https://github.com/reactiveui/Akavache
- https://robgibbens.com/resilient-network-services-with-xamarin/
- http://www.thepollyproject.org/
I’m pretty sure there are many resources around this topic, for all the major mobile platform and languages. I’m definitely not a Mobile developer, so if you have any comments or resource to share, please do :).
Cloud to App Sync
Sending data from the cloud to the app is way more tricky. You want to do it in the most efficient way, to spare bandwidth and device battery life, so you need a way to know what has changed since the last time that specific user and device synced. As data is surely stored in a database of some sort, you also need some efficient method on the database side to make sure you can quickly get everything that is new or changed and that is in the scope for that specific user/device. If your mobile application is successful, this means that you may literally have millions and millions of rows or documents to scan and check for changes.
Not an easy task: all hope is lost then? Just send back the whole data set and that’s it? Of course not! We don’t want to just be developers, but better developers, right?
Modern databases can help a lot in tackling this challenge. Azure SQL, for example, has a feature called Change Tracking that, guess what?, will take care of keeping track of changes for you.
Here’s a very high level of how it works:
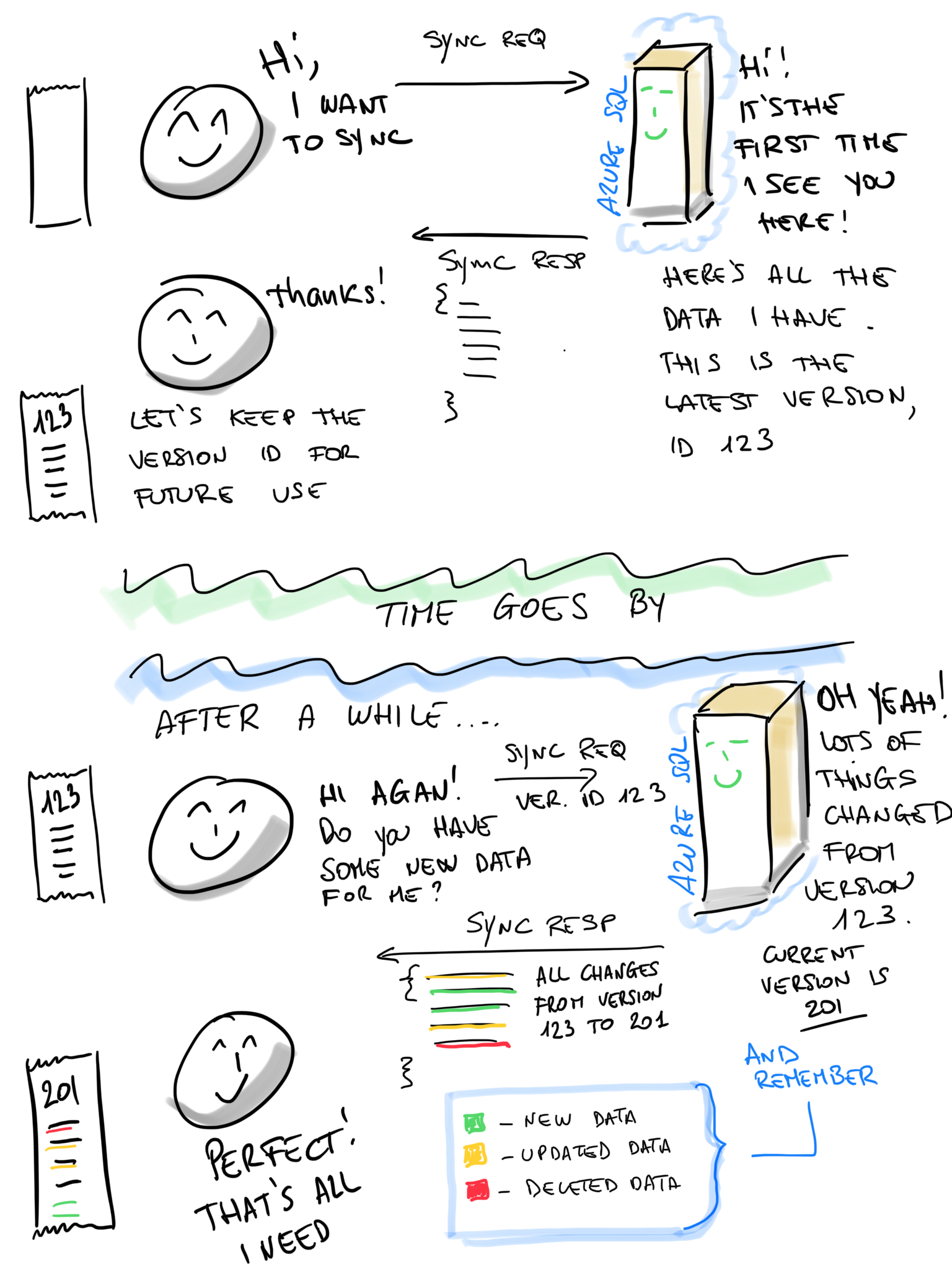
But let’s dive into it a bit deeper, to see how it can help us creating a nice API that, when called, will return all the data that has been inserted, updated or deleted since the last time it such API was called from a user/device.
The sample scenario
Imagine that you are creating an application to track your Running Sessions (Yep, that’s exactly what I was doing before joining Microsoft: https://www.sensoriafitness.com/). Many people loves running, hiking or cycling, so you are surely aware of application like Runtastic, Strava and the likes.
First Sync
The first time your application starts after being installed, it will need to query the server, (once the user has logged in), and download all the existing data for that user.
curl -s -k — url
https://localhost:5001/trainingsession/sync
Here’s the JSON you may expect to receive from the syncREST endpoint:
{
"Metadata": {
"Sync": {
"Version": 123,
"Type": "Full"
}
},
"Data": [
{
"Id": 10,
"RecordedOn": "2019–10–27T17:54:48–08:00",
"Type": "Run",
"Steps": 3450,
"Distance": 4981,
...
},
{
"Id": 11,
"RecordedOn": "2019–10–26T18:24:32–08:00",
"Type": "Run",
"Steps": 0,
"Distance": 4562,
...
}
]
}
The JSON document has two sections. The Metadatasection will tell you if you are receiving the Full set of data or just the change set, and an identifier of the version of data you are receiving. In the above sample, we are receiving a Fullset, that comes with the version number 123. This number has no special meaning: it just represent a number associated with the current version of data. Is a way, for us, that we’ll use in future to tell the server that we won’t need all that data again, since version 123 it’s our starting point. In a hypothetical timeline, this is our “T0”, the start of our timeline. We’ll just need to get the changes from there and on.The Data section contains all the data we need to use to populate our application so that it will show all past Running sessions. Nothing complex here. You may literally save that part of the JSON as is, and use it in your app. I think it will still be better to save it into something like SQLite, but that’s up to you.
Subsequent Syncs
The users loves our application and they keep using it. We also created a nice website where they can play with their data, slicing and dicing to analyze their performances, adding title and notes to their sessions, and using some clever AI service to analyze their performance and get a customized plan to improve in specific areas. Of course, some of the processing needs to be done on the cloud and the sent back to the app. So the app needs to sync again, this time not to send new sessions, but to get updates from the cloud.
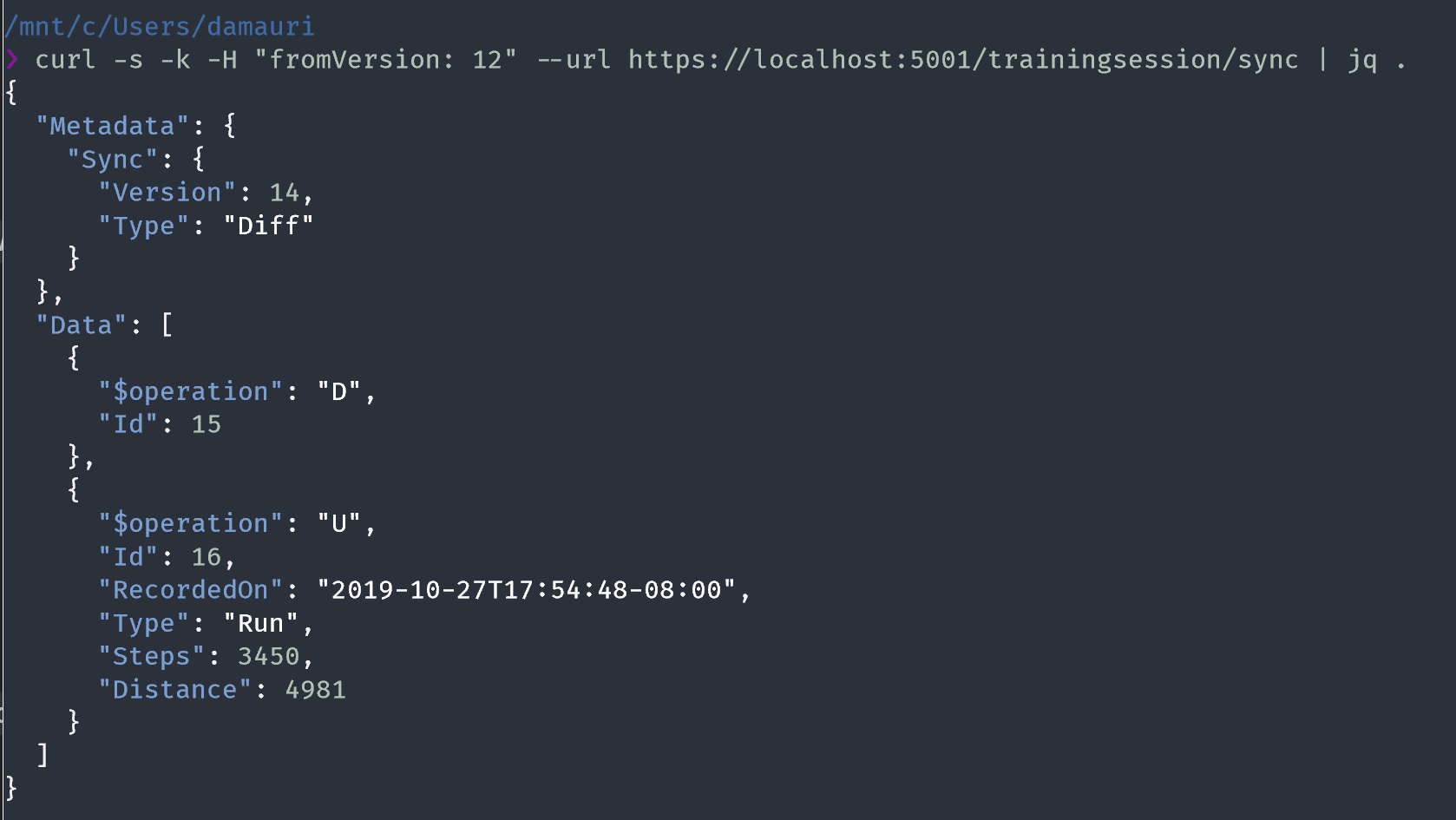
This is what it can expect to receive, exactly from the same sync endpoint it called before. This times the app call the REST endpoint sending also the version number it has received before: 123.
curl -s -k -H “fromVersion: 123” — url
https://localhost:5001/trainingsession/sync
The answer will be something like this:
{
"Metadata": {
"Sync": {
"Version": 201,
"Type": "Diff"
}
},
"Data": [
{
"$operation": "U",
"Id": 11,
"RecordedOn": "2019–10–26T18:24:32–08:00",
"Type": "Run",
"Steps": 4346,
"Distance": 4562,
...
},
{
"$operation": "I",
"Id": 67,
"RecordedOn": "2019–10–28T17:19:47–08:00",
"Type": "Run",
"Steps": 4866,
"Distance": 4671,
...
}
]
}
The server is sending us only a Diff data set, which contains all the changes we need to apply locally, to move the version we have, 123, to become the same as the current data, which is represented by the new version number, 201.
Within the Data section, there is a new element, $operation, that tell us if that data must be Inserted, Updated, or Deleted, so that, if we’ll apply all changes to local data (version 123) it will become the same as the current data on server (version 201).
It’s up to us to apply the received data, with the specified operations, to our local data set, as how those changes will be applied depends on the technology we decided to use to store our data locally.
Wouldn’t it be nice…
…if the generation of the JSON, the decision if a row must be inserted, updated or delete, can be done by the database for us? We just pass the starting version to the database, which it will check the difference against the current version and…well, done.
Yes, it would be nice. No, better, it would be amazing…because figuring out what are the changes to be sent to each different user/device is really not a simple task.
Let me explain why with a simple example: for UserA/Device1, it might be that some data doesn’t even need to be sent at all, because, since its last sync, that data was inserted and then deleted, so there is no point in sending it at all. But maybe for UserA/Device2 things are different. Let’s say it was synced after the insert but before the subsequent delete of the same document…as you can guess, UserA/Device2 only needs to be acknowledged of the delete operation.
Now imagine a lot of users and a lot of devices. How time consuming doing something like that could be? Yeah, very time consuming.
Well, luckily for us Azure SQL does exactly this. Change Tracking is an amazing technology that will make everything I just explained as easy as:
select
ct.SYS_CHANGE_OPERATION as '$operation',
ct.Id,
ts.RecordedOn,
ts.[Type],
ts.Steps,
ts.Distance
from
dbo.TrainingSession as ts
right outer join
changetable(changes dbo.TrainingSession,
@fromVersion
) as ct
on ct.[Id] = ts.[id]
The changetable operator will take care of everything for you, exactly as we dreamed of. Just pass in the version you want to sync from, and it will give you all the operations you need to do to sync with the current version, whatever it is.
Now, we’re all developers here…so we really don’t want to deal with tables, rows and all that stuff. How to turn that into JSON?
We learned how to do that in the previous articles. This time is a bit (just a bit, I promise!) more complex as we want to create a JSON like we discussed before, and we don’t want to use the JSON as it comes out from Azure SQL.
Azure SQL allows to define the JSON in exact shape you need, thanks to FOR JSON PATH:
select
@curVer as 'Metadata.Sync.Version',
'Diff' as 'Metadata.Sync.Type',
[Data] = json_query((
select
ct.SYS_CHANGE_OPERATION as ‘$operation’,
ct.Id,
ts.RecordedOn,
ts.[Type],
ts.Steps,
ts.Distance
from
dbo.TrainingSession as ts
right outer join
changetable(changes dbo.TrainingSession,
@fromVersion
) as ct
on ct.[Id] = ts.[id]
for
json path
))
for
json path, without_array_wrapper
Isn’t that amazing? Just think to how many hours of work you have just saved!
See it in action!
If you are interested and want to see that in action yourself, you can find a working sample where:
Azure-Samples/azure-sql-db-sync-api-change-tracking
you’ll be able to deploy it in minutes.
Everything is done in C#, but doing it in Python should be quite simple, as you can start from here:
Building REST API with Python, Flask and Azure SQL
and make the few required changes.
Enjoy!