Streaming at Scale with Event Hub Capture
Probably the easiest way to implement lambda/kappa architectures on Azure 04 Feb 2019
Lately I’ve worked a bit on the Streaming at Scale repository on GitHub in order to add what I feel is probably the easiest options to ingest large amounts of data and query it right away: Event Hub Capture + Apache Spark or Apache Drill. Interested in figuring out how to build a very simple (yet perfectly working) lambda/kappa architecture in just a few minutes? Read on.
Capturing Events
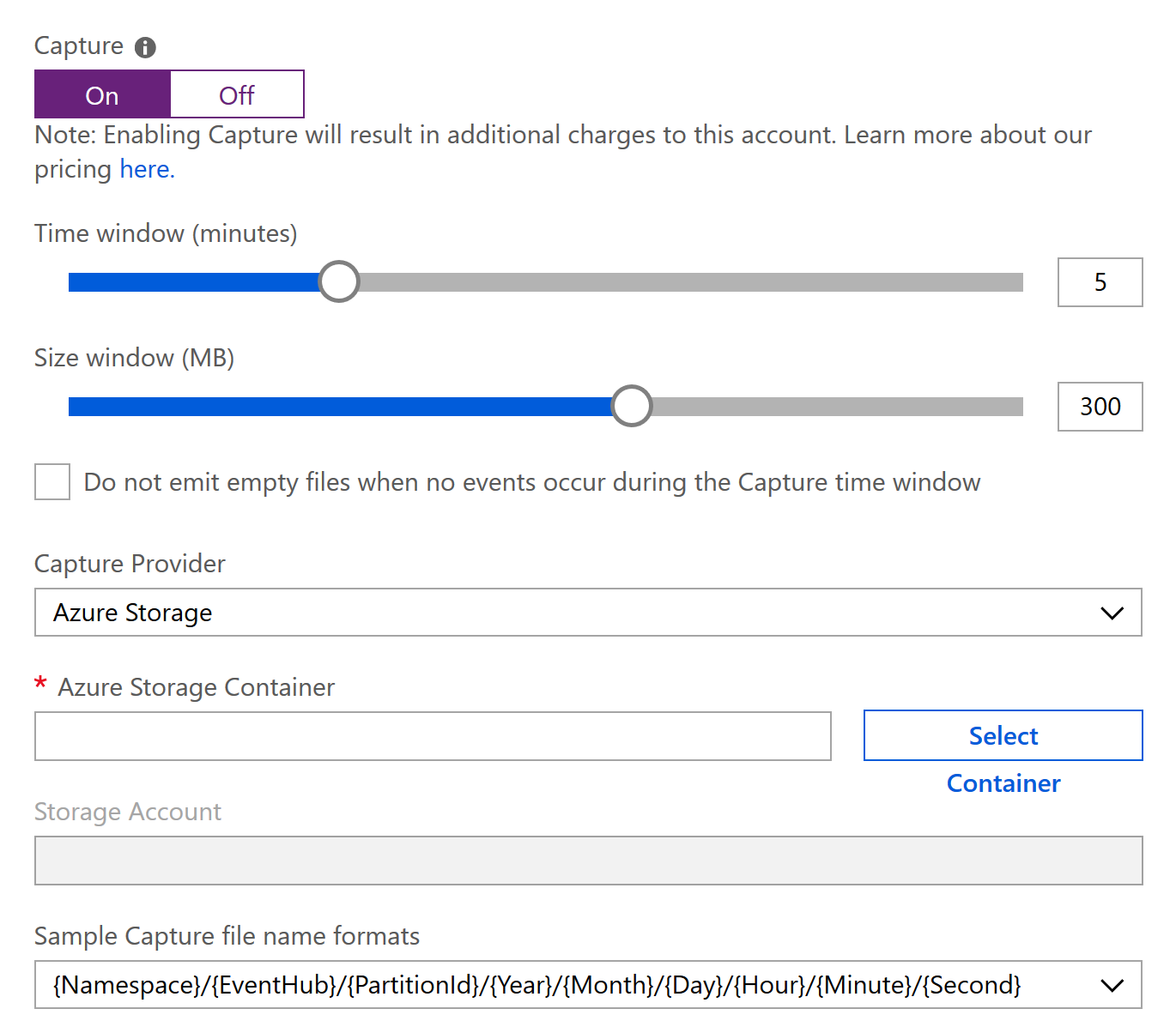
A very nice feature of Event Hub, called Capture, allows the automatic capturing of events streamed through Event Hub. Documentation is great so I really encourage you to take a look at it here:
Capture streaming events - Azure Event Hubs
In brief, you just have to configure how frequently you want to capture to happen, and where you want to save all the event captured in that time frame. That’s it. Output is an Avro file and so it is usable right away by almost any Big Data tools, like Apache Spark or Apache Drill.
Incremental As-Fast-As-Possible ETL/ELT
There are some cases where you don’t really need to do a lot of transformations on the fly. What you really need is to do an incremental load of your data warehouse or data mart. And you want to do it as soon as possible, but you don’t really need it real-time. An update every minute, or even every hour, would be more then enough. The reasons to do that can be various, and both technical or business driven.
I’ll leave business driven ones out of the discussion as it would be of topic: enough to say that each business has its own rhythm-of-business,and you can’t just force it to become a near real-time by putting some technology in place.
So let’s focus more on the technical drivers. One of the most common I’ve found is that, sometimes, the overhead to just execute the ETL/ELT can be huge, and doing it for just a few rows coming in in real time is not worth the effort. It is just better to wait for a bucket of data to arrive and the act on the set as a whole. Another reason is the need to invoke some 3rd party system that may not be able to sustain high volumes of small data and so it is just better to, again, gather a bunch of data and then invoke that limited resource once for all gathered data.
I agree that these situations are not that frequent, but they do happen from time to time, so it is good to have a nice way to solve the challenge in a very easy and straightforward way.
Rewinding Time
Another case is that you what the ability to (re)process data sent to Event Hubs that is out of the retention window, which is 7 days maximum at present time.
Event Hubs capture store all ingested data which can be easily replayed just by reading it via any Avro libraries. Here’s an example of how to do it using Python:
Read captured data from Python app - Azure Event Hubs
This ability can be extremely useful for example when you want to:
Complete Solution
As usual the complete solution is available on GitHub. In the sample I used Apache Drill to show how to consume captured data, since a sample done with Apache Spark would be really really simple, thanks to the tight integration of Azure with Databricks. But let me know (via GitHub Issue) if a Spark sample is needed too. I’ll be happy to add one.