PowerBI and Azure Databricks — 2
Easier configuration and DirectQuery support with the Spark Connector 14 Feb 2018
Just a couple of days after I published the article that describes how to connect to Azure Databricks with PowerBI via the ODBC connector, I received an email from friends (Yatharth and Arvind) in the Azure Databricks and AzureCAT team that told me that a better and easier way now available to connect PowerBI to Azure Databricks was possible.
Not only this new way is way simpler and lightweight, but it also enables usage of DirectQuery to offload processing to Spark, which is perfect when you have a real huge amount of data, that doesn’t make sense to be loaded into PowerBI, or when you want to have (near) real-time analysis.
The PowerBI connector to be used to go this way is, as you may have guessed, the Spark connector:
Configuring the connector, compared to all the setup needed with ODBC, is really a breeze. All you have to specify is the server and the protocol. Protocol must be set to HTTP:
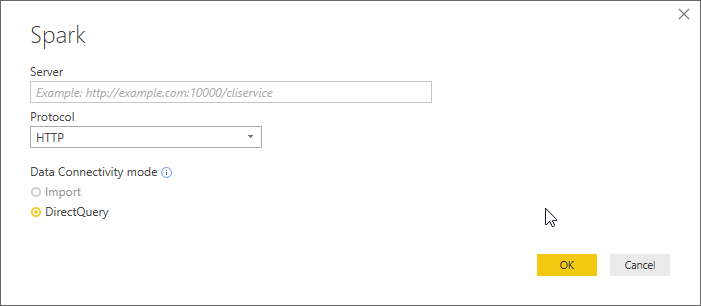
Setting the server is just a bit tricky. Information can be found in the JDBC/ODBC pane available in the Configuration page of your Azure Databricks Spark cluster:
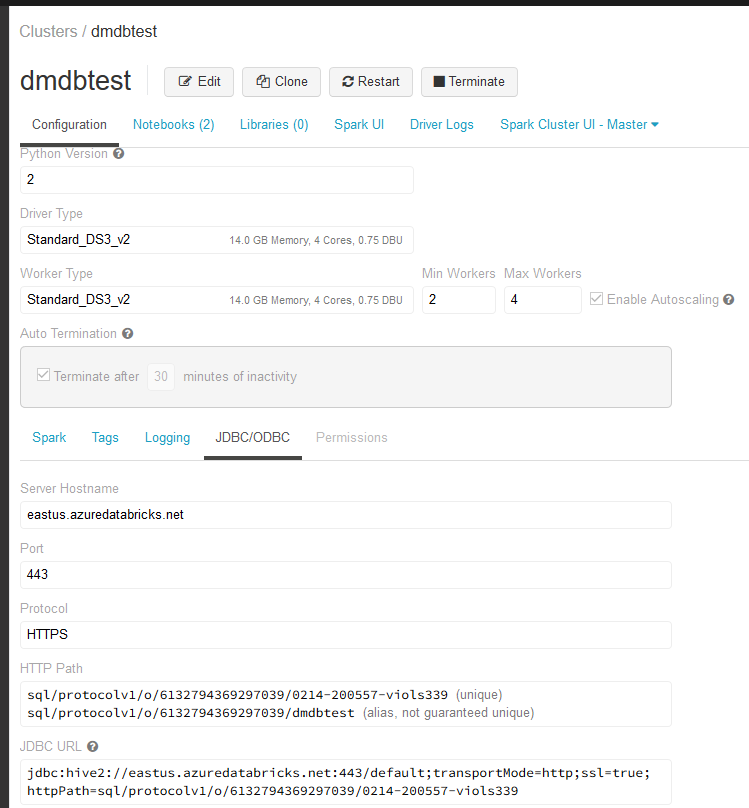
The url needs to be constructed following this procedure:
- from the JDBC url take the hive2 server address, excluding the database name. In the shown example would be:
hive2://eastus.azuredatabricks.net:443/ - Replace
hive2withhttpsso that the url becomes:https://eastus.azuredatabricks.net:443/ - Now concatenate that string you the other one you can find the in HTTP Path box. In the sample is:
sql/protocolv1/o/6132794369297039/0214-200557-viols339or
sql/protocolv1/o/6132794369297039/dmdbtest
The final url would be:
https://eastus.azuredatabricks.net:443/sql/protocolv1/o/6132794369297039/0214-200557-viols339
Now just insert it into the Server textbox of PowerBI Spark connector configuration window, as mentioned before, and you’re almost done.
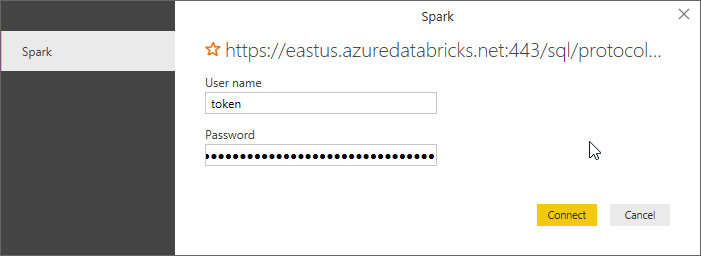
Credentials are issued and managed via the Personal Token, exactly as explained in the ODBC article. So just insert the token user name (remember that you really have to literally insert “token” as username) and then the generated token as password:
After that it will just works, now also with DirectQuery:
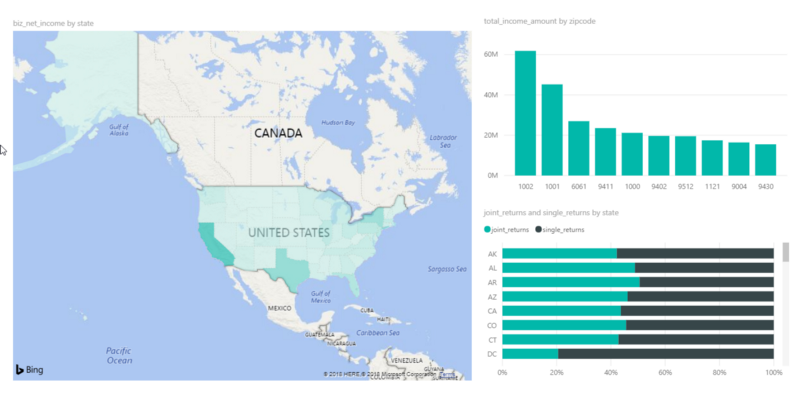
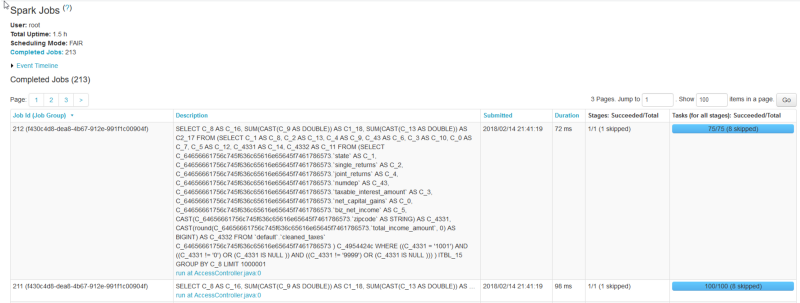
Here a glimpse of what’s happening behind the scenes, with the SQL queries sent to Spark when DirectQuery is used:
Official documentation will be updated soon, in the meantime, for all those like me who are eager to play with Azure Databricks and PowerBI, I hope this helps.