PowerBI and Azure Databricks — 1
Using PowerBI to explore and visualize data stored in Azure Databricks using ODBC connector
07 Feb 2018
Please note that from middle of February 2018 connection to Azure Databricks is also possible via Spark connector as described here, which is now the recommended approach. Continue reading this article if you’re interested in setting up a connection via ODBC.
Please note that from middle of February 2018 connection to Azure Databricks is also possible via Spark connector as described here, which is now the recommended approach. Continue reading this article if you’re interested in setting up a connection via ODBC.
I’ve recently changed my role and as a result I’m now again 100% focused on my first love, data and databases.
Among all the cool stuff released in the last two years in the data space, for which I haven’t had enough time to play with, there is Databricks, the Spark distribution, created by the creator of Spark themselves. Spark has also reached version 2.x and I really wanted to give it a test run, to play with the new features by myself.
Since Databricks is available on Azure, I just created new cluster and to get confident with Azure Databricks I firstly did the “Getting started - A Gentle Introduction to Apache Spark on Databricks” tutorial. It’s very introductory and allows you to get confident with terminology, concepts and usage of Notebooks. If you already used tools like Jupyter or Apache Zeppelin you’re already familiar with the Notebook idea and you can go through the tutorial real quick.
After the first tutorial, the second one is the “Apache Spark on Databricks for Data Scientists”.
Once I finished the tutorial I immediately thought that would have been great to connect to the available data using PowerBI. Doing data exploration and visualization on the notebook is great but I wanted to do some interactive data exploration. In addition I also wanted to create a nice dashboard that can be easily shared with non-tech users, and for these things PowerBI (or other tools like Tableau) is just a killer application.
So, how do you connect PowerBI to Spark on Azure Databricks? There is a complete documentation here:
Power BI Service and Desktop - Databricks Documentation
And following it is really not difficult, but it may be a bit tricky, if you’re not familiar with the PowerBI ecosystem (Service, Gateway and Desktop). If you just want to connect your PowerBI desktop client to Spark on Azure Databricks, just keep reading.
First of all make sure you have the latest PowerBI version installed on your machine:
How to Get Started - Microsoft Power BI
and then download the Apache Spark JDBC/ODBC driver:
Apache Spark ODBC Driver Download - Databricks
Make sure you select the Windows (ODBC) version and then proceed to install it. Since I’m using PowerBI x64, I just installed the 64-bit one.
Once installation is done, go and open the ODBC Data Source Administrator:
and create a new DSN. Choose a “User DSN” if it’s only for you, or “System DSN” if other people on the same machine will be using it.
To create a new DSN click on “Add” and the select the “Simba Spark ODBC Driver”. After that you’ll see a window like the following:
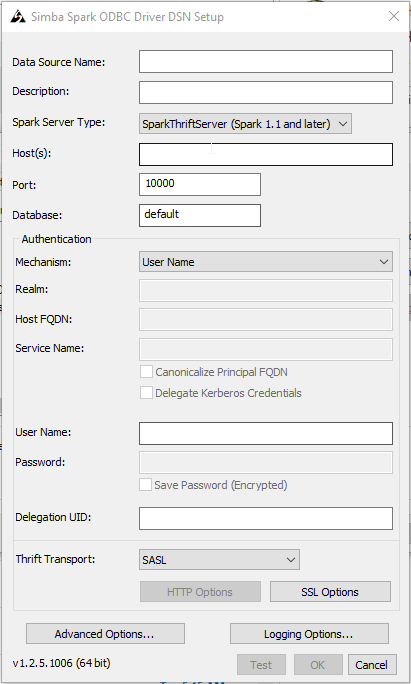
Since we’re connecting to a Spark 2.0 cluster, as you can verify in the “Configuration” page of you Databrick Spark cluster,

the ODBC “Spark Server Type” option needs to be set to the following:

The “Hosts(s)” and “Port” option must be set to the values you can see in the JDBC url (that is available in the “Configuration” page of the Spark cluster too):

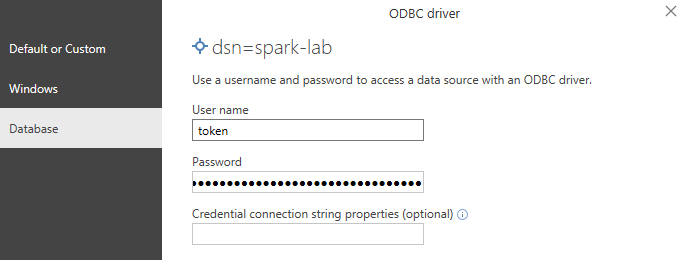
Azure Databricks allows authentication via unique users tokens. The ODBC Authentication mechanism needs to be set to “User Name ad Password” and the user name must be set to “token”. Literally, just without quotes.
The password is the token that can be generated on the Databricks portal by clicking on the user icon on the top right and selecting “User Settings”:
This will bring up the “Access Token” page. Just click on Generate New Token, specify the lifetime of the token and then copy the generated token somewhere. The token is something like:
dapi22622d65cda52cd1178d8f3233a025e5
This is actually the password you have to specify in the ODBC Driver:
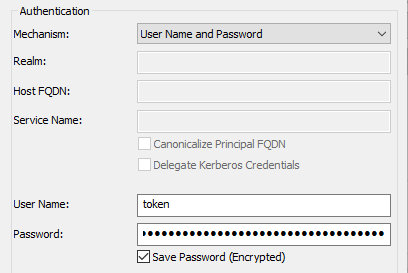
Authentication is now one. It’s now time to configure the Thrift Transport. It must be set to HTTP and then “HTTP Options” and “SSL Options” needs to be configured accordingly.
In the “HTTP Options” specify the HTTP Path you can see in the JDBC Url (or, again, in the Cluster Portal, Configuration Tab, HTTP Path section)
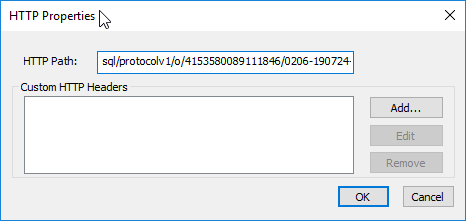
In the “SSL Options” just make sure you check “Enable SSL”.
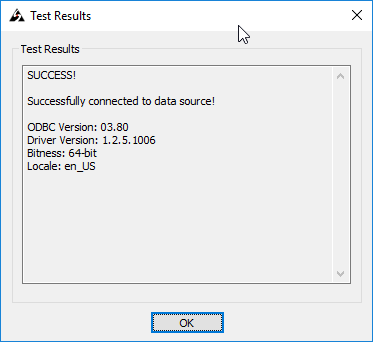
That’s it! Now click on the “Test” button to the test connection and you should be able to see a window like this (Just make sure your cluster is running and you don’t have any firewall blocking connections)
So far, so good, ODBC DSN is created. It’s now time to open PowerBI Desktop and get data from the Spark cluster by using the newly created DSN:
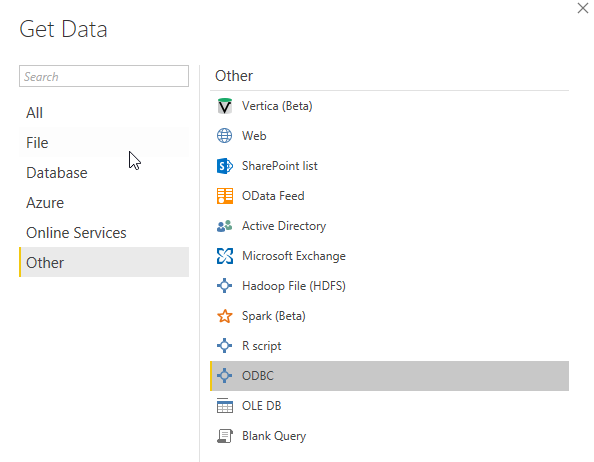
Make sure you select the DSN you created before
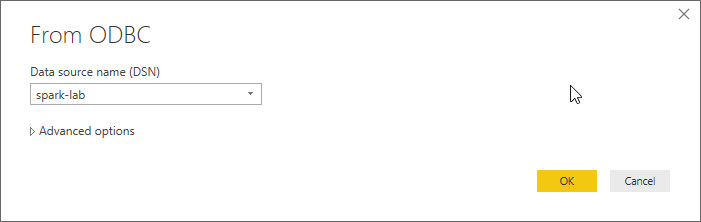
use the token as a password again when asked and make sure the user name is set to “token” (again, without quotes)
and you’ll be good to go!
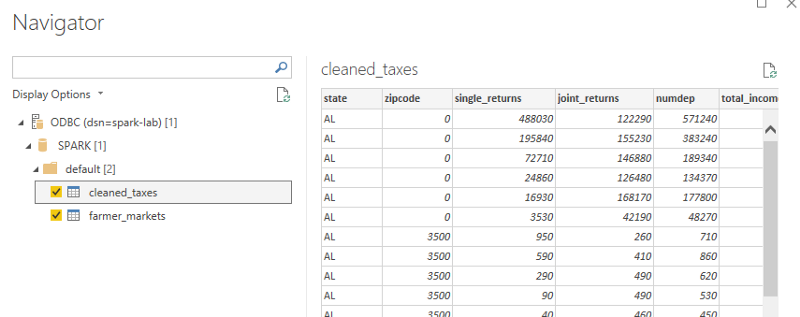
As you may notice I’ve also added the “farmer_markets” as a non-temporary table, so that I can do exactly what the tutorial tells you to do via Spark, but using PowerBI this time.
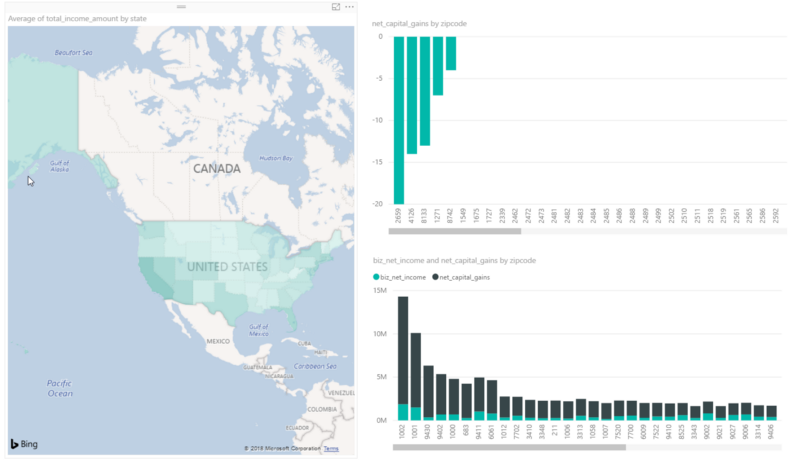
And now you can easily explore and visualize data, PowerBI way: