Real-Time Materialized Views with Cosmos DB
Keeping data updated using the Change Feed in a Serverless world 16 Apr 2019
In many scenarios, and especially in ones where data is streamed constantly from sources, the ability to quickly query incoming data is a key factor.
A good, and different from the usual IoT or Microservices example, is in the gaming industry. For example in a multiplayer game player points are constantly updated and sent as a stream of data. By reading that stream it’s possible to create and maintain a view of the points scored by all players and, for example, show it in a leader board.
Back to usual and more common samples, in an IoT scenario the last status reported by all monitored devices could be used to create a real-time dashboard to show how each device is performing.
In a microservices scenario (where also maybe the CQRS pattern is used) the ability to have an aggregated and constantly updated view of an entity is really useful to make sure that anyone who needs to access the complete set of information pertaining to that entity can do it safely, correctly and easily.
One of the well known pattern used to implement such feature is know as Materialized View pattern. With example provided above I think you should now get the idea of why such pattern is so useful, but if you need even more detail, there are plenty of articles on the subject. Here’s some I found useful:
The question now is: how can I implement it in Azure, using a purely serverless approach, with the lowest complexity possible?
“Lowest complexity possible” here means that we should try keep the number of used technologies to the minimum. For example we already know the we could use Apache Kafka or EventHubs to implement a Lambda or Kappa architecture that would allow us to solve the problem. But will it be the simplest solution possible, or there are alternatives?
Change Feed
While consuming the stream of data is a great option, you also want to be sure to capture the raw data into a database of your choice. What if we could just have both at the same time? This will make the overall solution easier and simple as we won’t have to process the stream on one side and store the data somewhere for long retention and analytics workloads on another. Luckily for us, some databases, Cosmos DB included, provides this option by publishing all the changes done to the data contained therein, as a stream of changes. The Change Feed:
A Sample Application
A sample application is available here:
Azure-Samples/cosmosdb-materialized-views
The sample data simulates an IoT environment, even though, as said before, the Materialize View pattern can be applied to any scenario and industry.
Data is generated by a simulator and written directly to Cosmos DB. This will ensure that we will always capture and preserve the raw data. So the first requirement of any data-related solution — do not lose any data — is already satisfied.
Preserving data is not enough, though: we also need to make sure that any user connecting to a monitoring application to check the status of a specific device can do it really quickly and in the cheapest way possible, it make sense to create a view for each device that contains all the information needed and keep it updated as soon as data for that specific device is written to the database.
Using the Change Feed this can easily be done. Using the Change Feed with Azure Function this can done in an even easier way. All is needed is to create an Azure Function and use the Cosmos DB Trigger binding: it will automatically connect to the Change Feed and process it for us, calling the function as needed.
Azure Cosmos DB bindings for Functions 2.x
Since Azure Function can scale automatically, we just created a scale-out parallel processor that can process data at scale:
The Change Feed processor library handles all of the orchestration with regard to partitioning and exposes a global feed to process changes, so you shouldn’t have to worry about partitioning details yourself. You just have to know that documents will be presented to you in the correct sequence. Azure Functions binding is built on top of the change feed processor; so same applies for the Azure Functions integration. This means that, in our sample, as long as we partition data by device id, we will always get the document in the correct sequence and that we don’t have to worry about potential inconsistencies.
Materialized Views
In the described sample there are two views for data being constantly streamed by IoT devices that could be really useful.
Device View
In the sample there are two different materialized views. One is created per each device, and contains only data related to a specific device. This helps to quickly and efficiently get the status, along with additional aggregated data, of the device someone or something is interested it. Perfect in the scenario where someone is using an app to check the values of a power meter, for example, or the status of some machinery in an oil rig.
Global View
Another interesting set of data to keep updated as quickly as possible, is a global view of all devices, so that for each device the last status reported is aggregated and made available in a very easy and, again, efficient, way. This view is just perfect to create a global dashboard that shows the overall status of a complex machinery, for example.
Updating the Materialized Views
Within-Partition Updates
As mentioned before, Change Feed assures that all changes related to data in a partition is processed in order. In the IoT sample we’re using, the raw data collection is partitioned by DeviceId. This guarantees that all changes made to a device will be received and processed in the correct order and that only one function will ever write data into the materialized view created for that specific device.
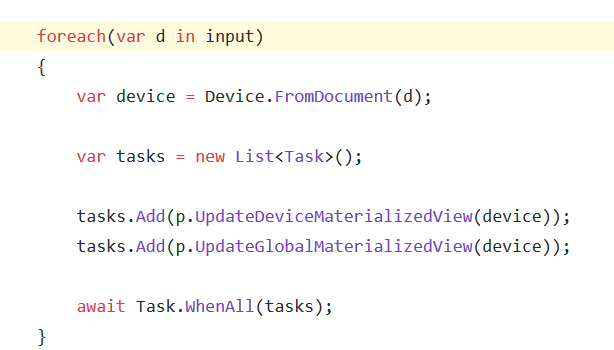
There is basically no complexity here. The Change Feed is consumed by the Azure Function that creates or updates the materialized view for the device it is processing data for and that’s it. As you can see the code for the method is really minimal.
As soon as data from Change Feed is processed, the function looks for an existing materialized view for the device who just sent some data. If one already exists, it is read so that existing data could be used to updated the view, otherwise a new view is created.
There is no need for concurrency control here as, since data is partitioned by Device Id, all changes for the same device will arrive in order and only one function at time will process that data. Basically data is serialized on per-device basis so there are not chances of conflicts.
Cross-Partitions Updates
Here this are a little more complex, but really not that much. If you are used to the concept of Optimistic Concurrency Control, you already are aware of the fact that
In Cosmos DB the smallest update possible is the entire document
In Cosmos DB the smallest updated possible is the entire document, so we need to make sure that if we update only a portion of it, the other parts that we don’t update are not changed from the last time we read the document. If they were, in fact, we would overwrite them with old data, creating an inconsistency known as lost updates.
In order to make sure such inconsistencies do not happen, we need to detected them in first place. The ETag system property is here to help:
Database transactions and optimistic concurrency control in Azure Cosmos DB
As you can see in the code, there is a retry logic that uses the ETag to make sure that when the updated document is written back to the database, the value is the same as the one we read earlier, meaning that the document hasn’t been changed in the meantime.
If an updated document is detected, the entire process of read-update-write is tried again for up to 10 times. After that the function simply gives up and generate an exception. In a real world scenario is up to you to decide what to do. You may want to put the document in a dead-letterqueue to make sure you retry again at some point or you change just change the logic and instead of processing one change at time, as the sample is doing, by simply iterating over the changes:
You could batch some changes together so that you can update the global view by updating multiple devices at once. This will reduce the potential contention and so decrease the chances of having to handle inconsistency.
Another option is to chain Change Feed together: you could create a collection only to store Devices Materialized Views, monitor it via its own change feed and then use that change feed to create the Global Materialized View. If you’re not going to have millions of devices, you can put the Devices Materialized Views in just one partition to make sure you won’t have any concurrency problem when consuming that Change Feed.
For The Relational Guy
If you come from the relational world (like me), Change Feed is really nothing more then what is otherwise know as Change Data Capture. The ability to have a stream of changes coming from the database is amazingly useful and I was using it quite a lot also for creating near-real time updated Business Intelligence solutions. I just discovered that there is also a tool called Debezium that will enable this feature, feed data into Apache Kafka, for the most common DMBS out there.
Sample Code
Full sample code, as usual, is available here:
Azure-Samples/cosmosdb-materialized-views
Enjoy!