Apache Drill, Azure Blobs and Azure Stream Analytics
With Apache Drill querying Azure Stream Analytics job results in real time is really easy 28 Aug 2018
Apache Drill is a very interesting project that, if you haven’t heard of it yet, allows you to use the ubiquitous SQL language to query…almost everything. Here’s the description on the website:
Drill supports a variety of NoSQL databases and file systems, including HBase, MongoDB, MapR-DB, HDFS, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, Swift, NAS and local files. A single query can join data from multiple datastores. For example, you can join a user profile collection in MongoDB with a directory of event logs in Hadoop.
So I though it would have been perfect also to query Azure Stream Analytics results. As you know, Azure Stream Analytics doesn’t support (yet?) a notebook-style environment (à-la Databricks Spark Structured Streaming for example), which makes development and testing a bit trickier. I already described a possible solution here:
Querying Azure Stream Analytics results in real time using Azure SQL
As said in the mentioned article, an alternative — and actually better — solution, than using Azure SQL, especially if you’re not really comfortable with it, is to use Apache Drill to read the output of Azure Stream Analytics and so check if the query produces the expected results.
Installing Apache Drill (on Windows 10)
Quite easy but with a big caveat if you already have installed Apache Spark. But let’s start from the beginning. Download and install Apache Drill as described here:
I used the embedded mode since I didn’t want to install an entire Hadoop cluster to run Drill. I just needed something easy, quick and cheap. The embedded mode, that can run on a single node, is just perfect for this use case. If your machine doesn’t have any Apache Spark or Apache Hadoop installed, you’ll be able to see something like this:
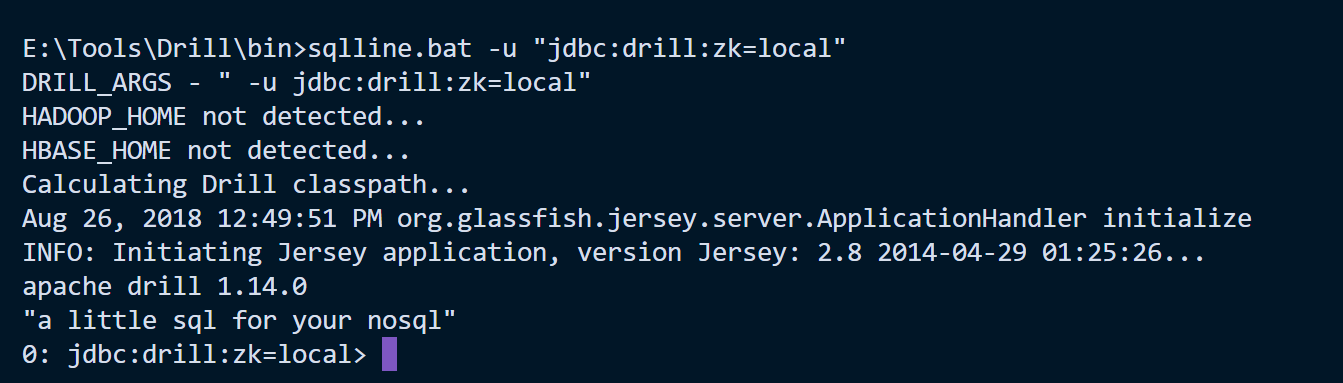
But if you have Apache Spark installed, for example, Drill will notice the HADOOP_HOME environment variable existence and will try to use it. The result is that it won’t be able to start Apache Zookeeper in local mode and you’ll get some errors:
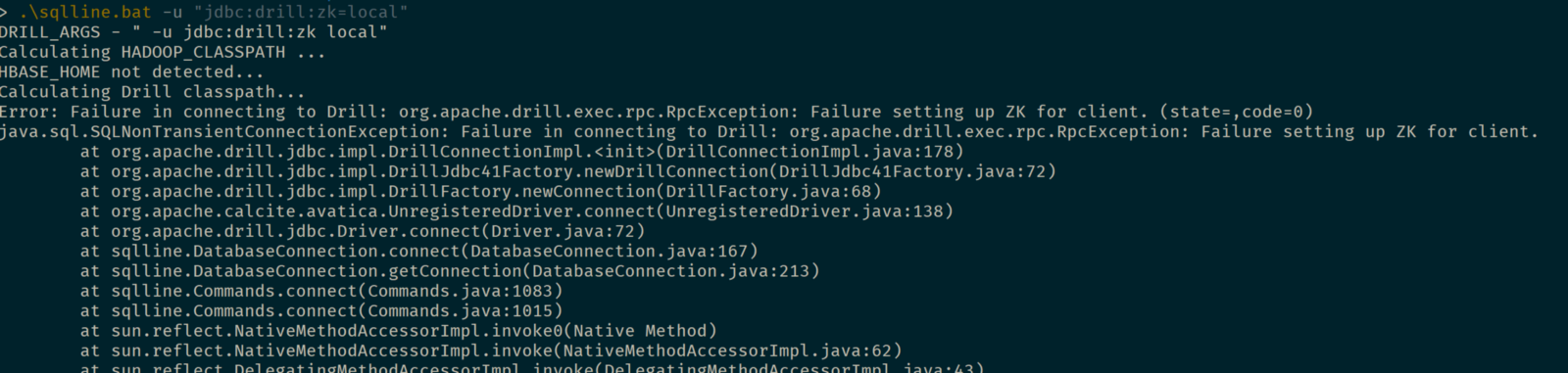
To solve the problem you can just unset the HADOOP_HOME variable just for the Apache Drill session, creating a .bat file like the following:
set "HADOOP_HOME="
sqlline -u "jdbc:drill:zk=local"
Installing Azure Blob Store JARs
To allow Apache Drill connect to Azure Blob Store, a specific Data Source needs to be configured.
https://drill.apache.org/docs/connect-a-data-source-introduction
Now, since explicit support to Azure Blob Store is mentioned even in the Apache Drill homepage, you would expect a nice documentation page, just like it exists for Amazon S3, that tells you how to configure everything, right? Wrong, of course.
The first step to make Azure Blob Store working with Apache Drill is getting the correct version of JARS. The one I found working are the following
download and copy them into jars/3rdparty folder. Easy right? The problem was just finding the correct combination of libraries versions that works…but you’re lucky since I’ve already done it for you, so you can just enjoy one more time at the pub, instead of spending hours just testing libraries.
Configuring the Storage Plugin
The libraries you just copied will be automatically picked up by Drill when needed…so it’s now time to tell it when it should do so. First of all you need to get the key value of the Azure Blob Store you what to access to. It can be done via the Azure Portal, the AZ CLI or via the nice Azure Storage Explorer:
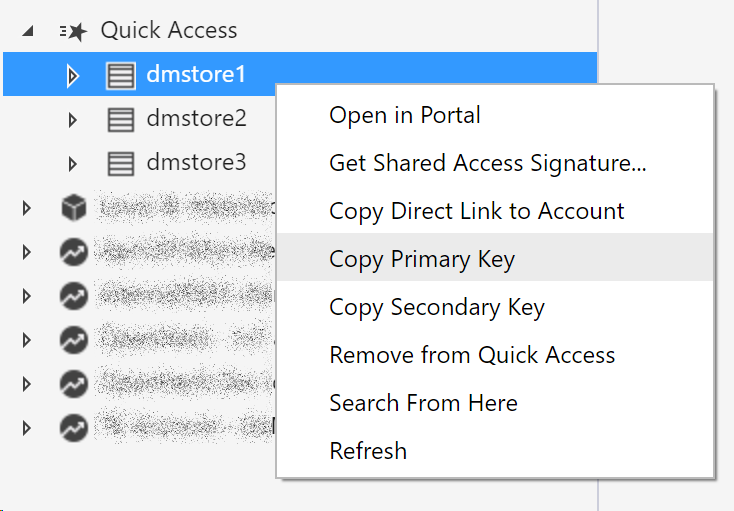
and then you change (or create if it doesn’t exists) the core-site.xml file in conf folder so that the XML will look like the following:
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<property>
<name>fs.azure.account.key.ACCOUNT_NAME.blob.core.windows.net</name>
<value>ACCOUNT_KEY</value>
</property>
</configuration>
replacing, of course, ACCOUNT_NAME and ACCOUNT_KEY with the Azure Blob Store account name you want to use and its own secret key.
You then have to create a new Storage Plugin. You can easily do that from the web interface (http://localhost:8047, just keep in mind the Drill must be running in order to access it), using the “Storage” section.
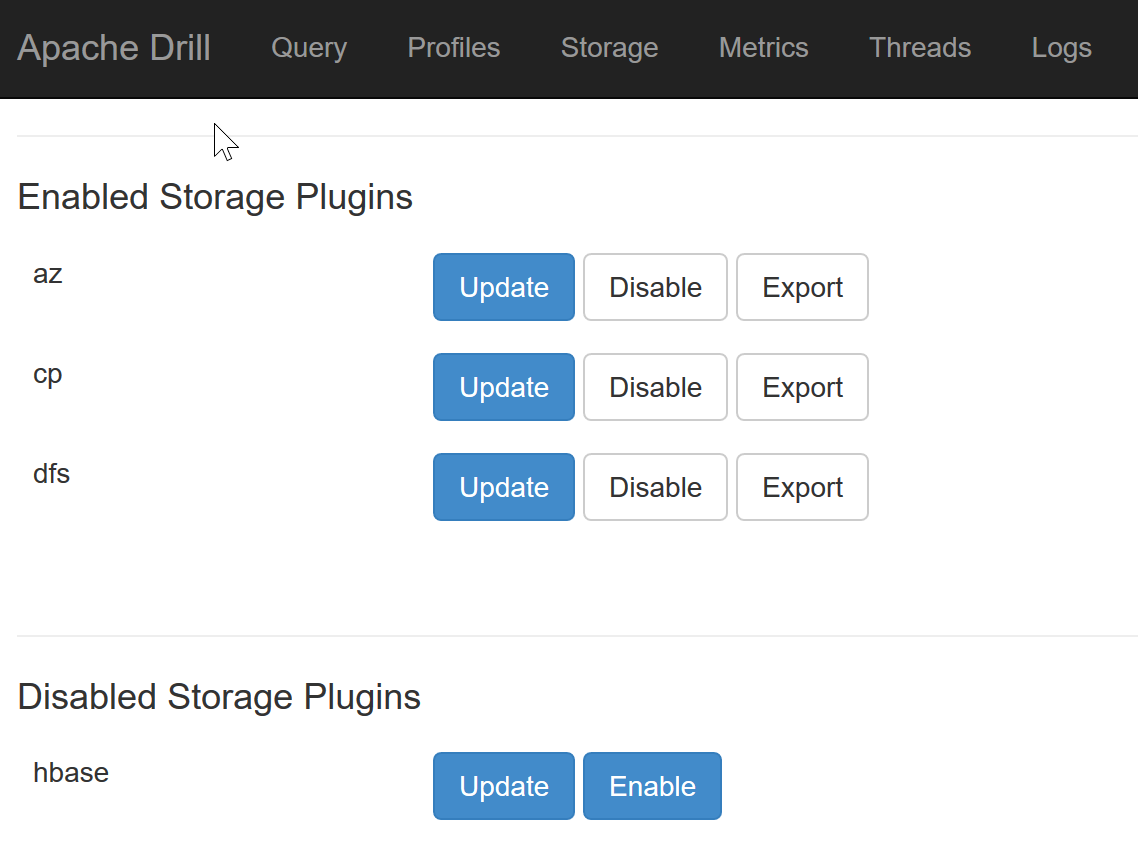
Create a new Storage Plugin, name it az for example, and then copy and paste the following configuration.
https://gist.github.com/yorek/35e2b693fb749f0388db22c2d814ddaf
The configuration has been taken from the dsl Storage Plugin already available in Apache Drill, and the connection has been modified to point to the Azure Blob Store. Of course, just like before, replace CONTAINER and ACCOUNT_NAME with your own values.
You should be able now to run Apache Drill and query the configured Azure Blob Store:
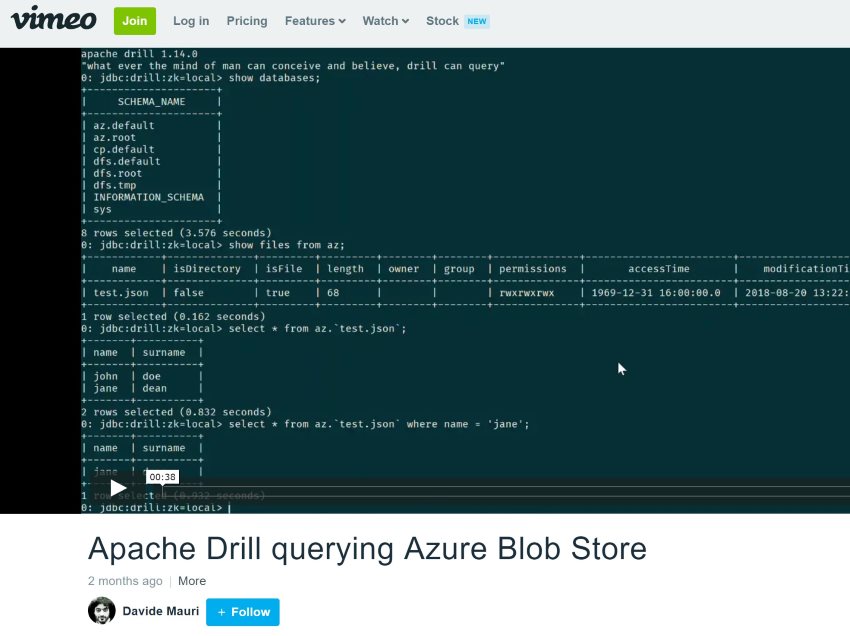
Querying Azure Stream analytics results
The most complex part is done now. All is needed now is to create an Apache Avro output for the Azure Stream Analytics job you want to monitor
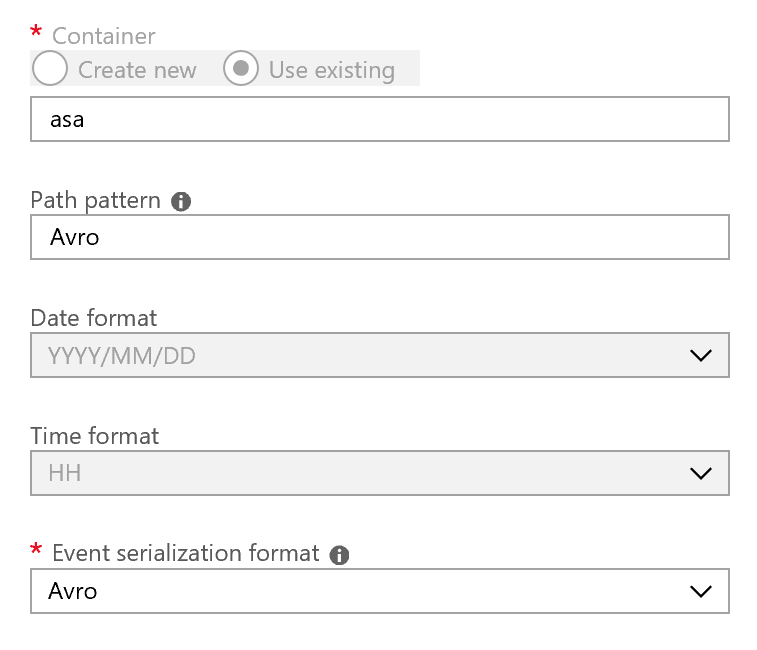
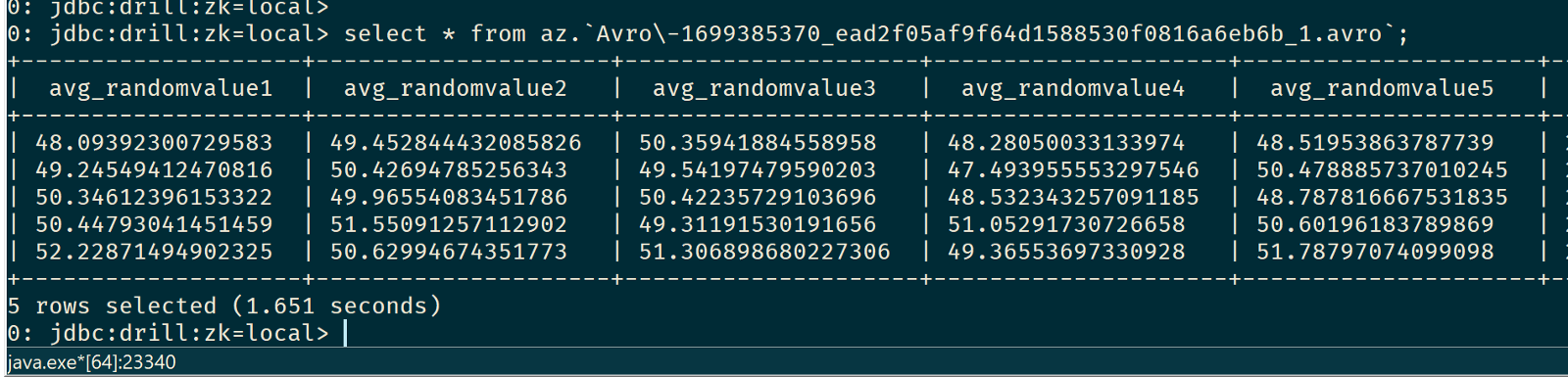
and then just use Apache Drill to query it. Of course you can also use other output format like JSON or CSV, but I suggest to use Avro since it comes with a schema and so you don’t have to do any cast to correct data types. Plus it is fast and compact which make it perfect for streaming scenarios.
Here’s Drill in action:
The alternative: Dockerize Everything
If you don’t want to mess up your machine with Java, Apache Drill and other stuff that maybe you’re not familiar with, but you still like the idea of using Drill to query streaming results, you can just go for the Docker way. In order to have Apache Drill up and running with the Storage Plugin correctly configured, a trick I used is to inject the file storage-plugin-override.conf *and *core-site.xml to have my most accessed Azure Blob Stores already configured and ready to be used.
You can grab the Docker solution here:
https://github.com/yorek/apache-drill-azure-blob
Make the changes you need to the aforementioned files, build the image with the provided drill-build.bat script and then run it with drill-run.bat. You’ll have Apache Drill running in a sec.