Azure SQL Managed Instances and Azure Data Factory: a walk-through
Making Azure Data Factory in Azure SQL DB Managed Instances work nicely together 10 May 2018
Now that Azure SQL DB Manages Instances are here, a lot of companies are trying to finally migrate their complex (multi-database, multi-dependency and database-centric) SQL Server database solutions to Azure SQL DB.
Once you have your Azure SQL DB Managed Instance running, you may also want to load or extract data from it. On-prem you may have used SQL Server Integration Services, and you may well continue doing so since SSIS Packages can run in the cloud thanks to Azure Data Factory:
Deploy SQL Server Integration Services packages to Azure
but maybe you just want to create a shiny new Azure Data Factory pipeline to orchestrate your data curation and data movement activities using SQL MI along with other Azure technologies (Spark, HDInsight, Azure Data Lake or anything else Azure offers), without having to resort to SSIS Packages.
Well, in order to allow Azure Data Factory be able to connect to an Azure SQL MI there are some steps involved that may be not obvious at the first time. This post is here to help.
Create an Azure Data Factory Self-Hosted Integration Runtime
The Integration Runtime (IR) is the engine that allows Azure Data Factory to perform all its activities. The default IR doesn’t provide VNet support and thus it can’t be used to connect to SQL MI VNet, which means that it can’t be used to move data in and out of a SQL MI.
Using VNet is possibile on via the a Self-Hosted Integration Runtime. Self-Hosted means that you can install the IR engine in an Azure VM that has been configured so that in can connect to the SQL MI and thus can be used as a bridge between the SQL MI VNet and the outside world. There are two options to do that. The first is to create the VM in a SQL MI VNet subnet as described here (section “Create a new subnet in the VNet for a virtual machine”):
Create an Azure SQL Database Managed Instance in the Azure portal
The other is to use an Azure VM in a separate VNet and peer it to the SQL MI VNet (look for the “Connect an application inside different VNet” section):
Connect your application to Azure SQL Database Managed Instance
Once you have the VM ready you can install the IR Engine. Create an Azure Data Factory (v2) resource and click on the “Author & Monitor” link to open the Azure Data Factory portal. Then click on the pencil icon on the left to open the “Authoring” pane and from there click on the “Connections” link you can find at the bottom left of the screen. The “Connections” tab will open, and there you’ll have also the “Integration Runtimes” section. Click on it and you should see something like the following:
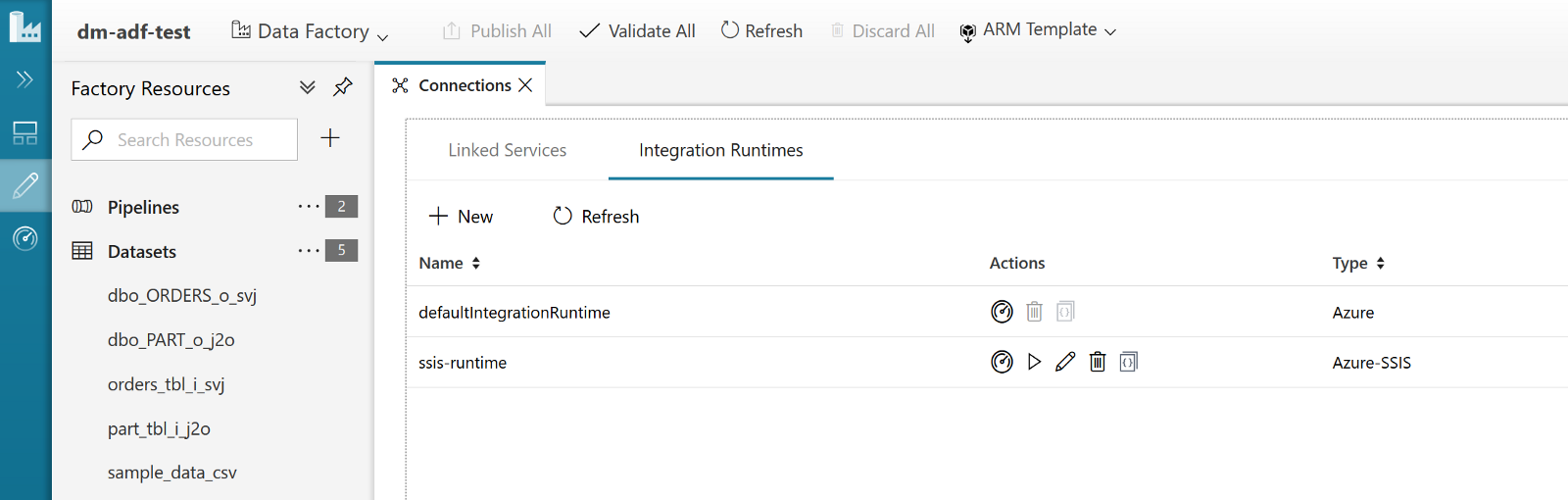
In my Azure Data Factory I can see also the ssis-runtime IR since I’ve enabled SSIS support. If you’ve just created the ADF resource and haven’t enabled SSIS support you won’t see that line.
It’s now time to create a Self-Hosted IR. Click on the “New” link an then select the first option: “Perform data movement and dispatch activities to external computers”:

The next option will ask you if the IR needs to access private resources. Of course it will, so make sure to select the “Private Network” option:

then give your IR a name and a description and finally you’ll see a page where you can download the integration runtime.
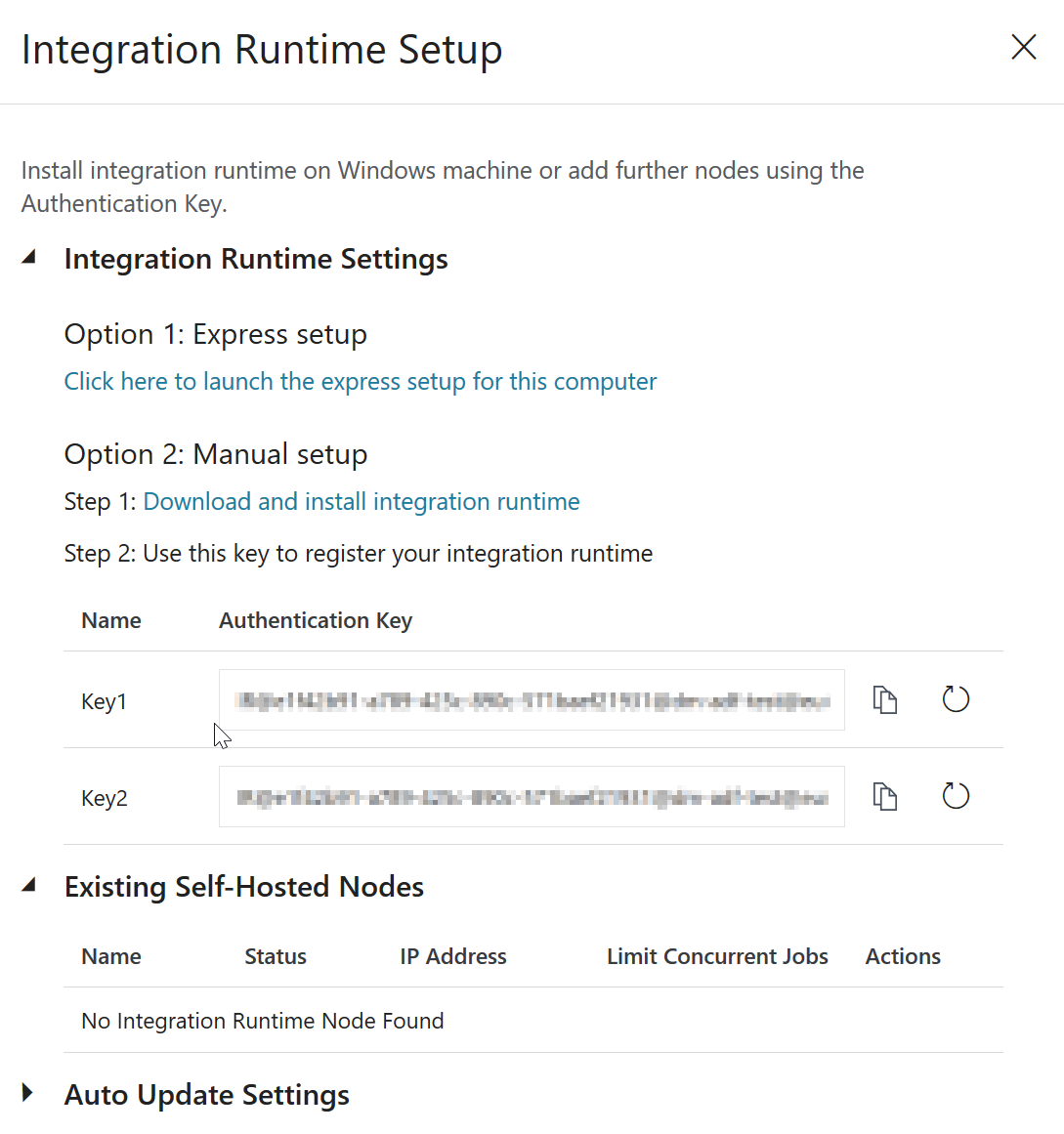
Download the installer via “Option 2: Manual Setup”, copy it to the VM you have created before and run it.
After the installer has finished its work it will ask for a key. Pick one of the key generated for you at the end of the creation of a Self-Hosted IR process and use it to register the engine:
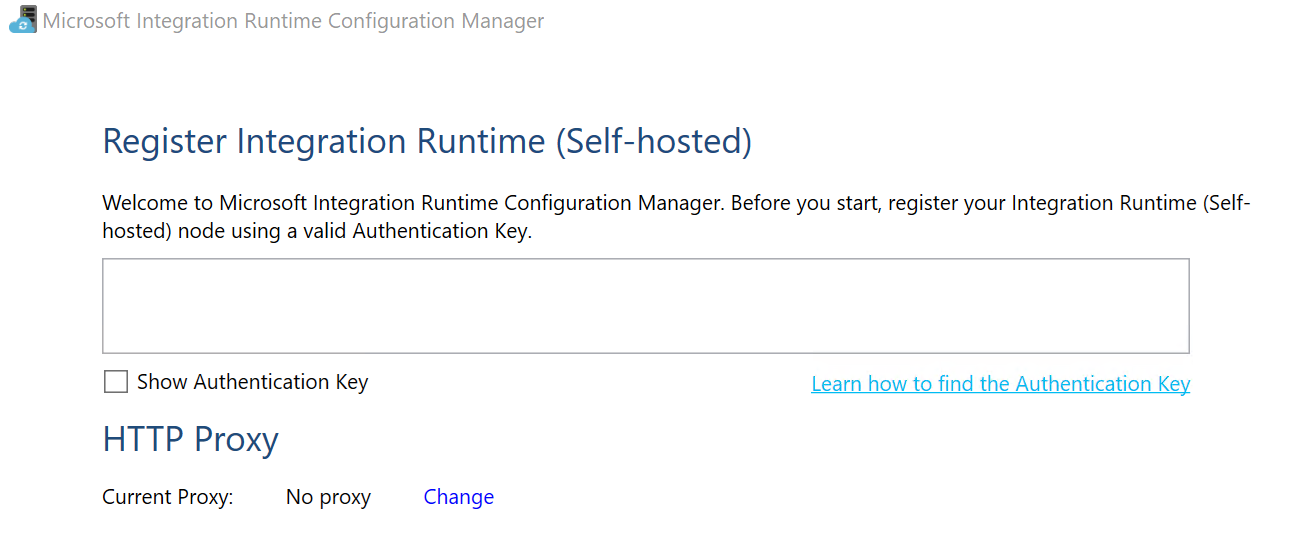
after a couple of seconds you should receive the confirmation that the IR has been registered correctly:
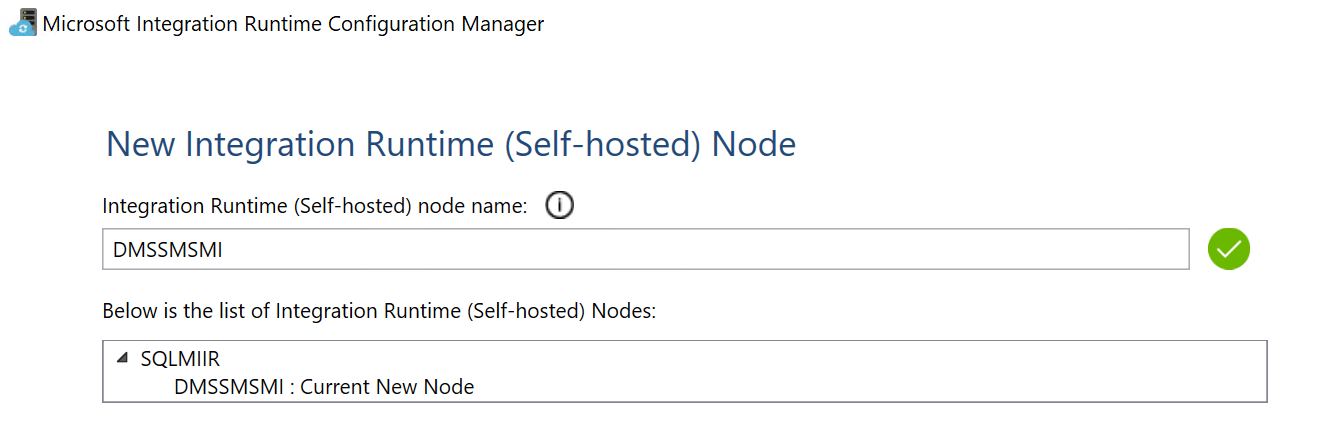
and you should also be able to see it in the “Integration Runtimes” list in the portal:

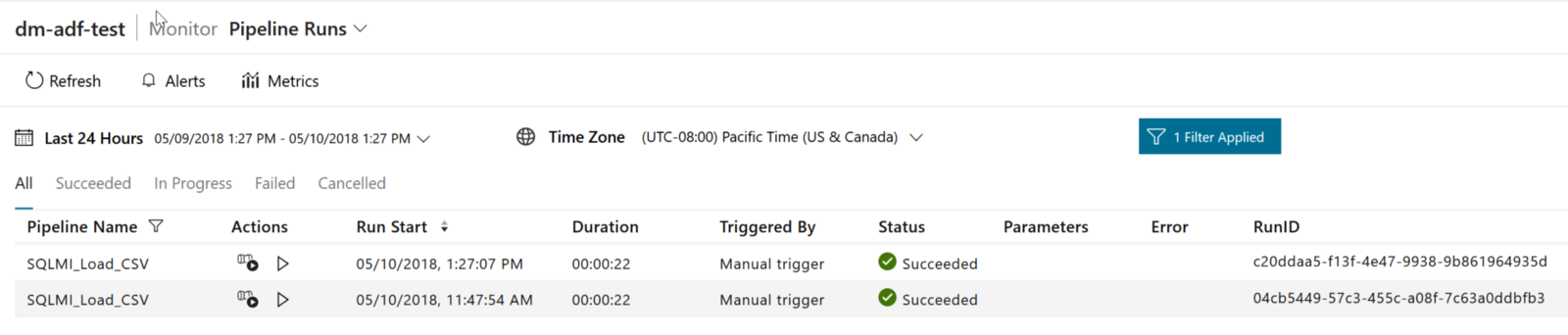
It’s now time to create a pipeline that uses it!
Load data into Azure SQL Managed Instance
The process is now just the same you follow to create a pipeline to load data into an Azure SQL Database with the exception that when creating the Linked Service that will allow pipelines to connect to Azure SQL you have to specify the newly created runtime:
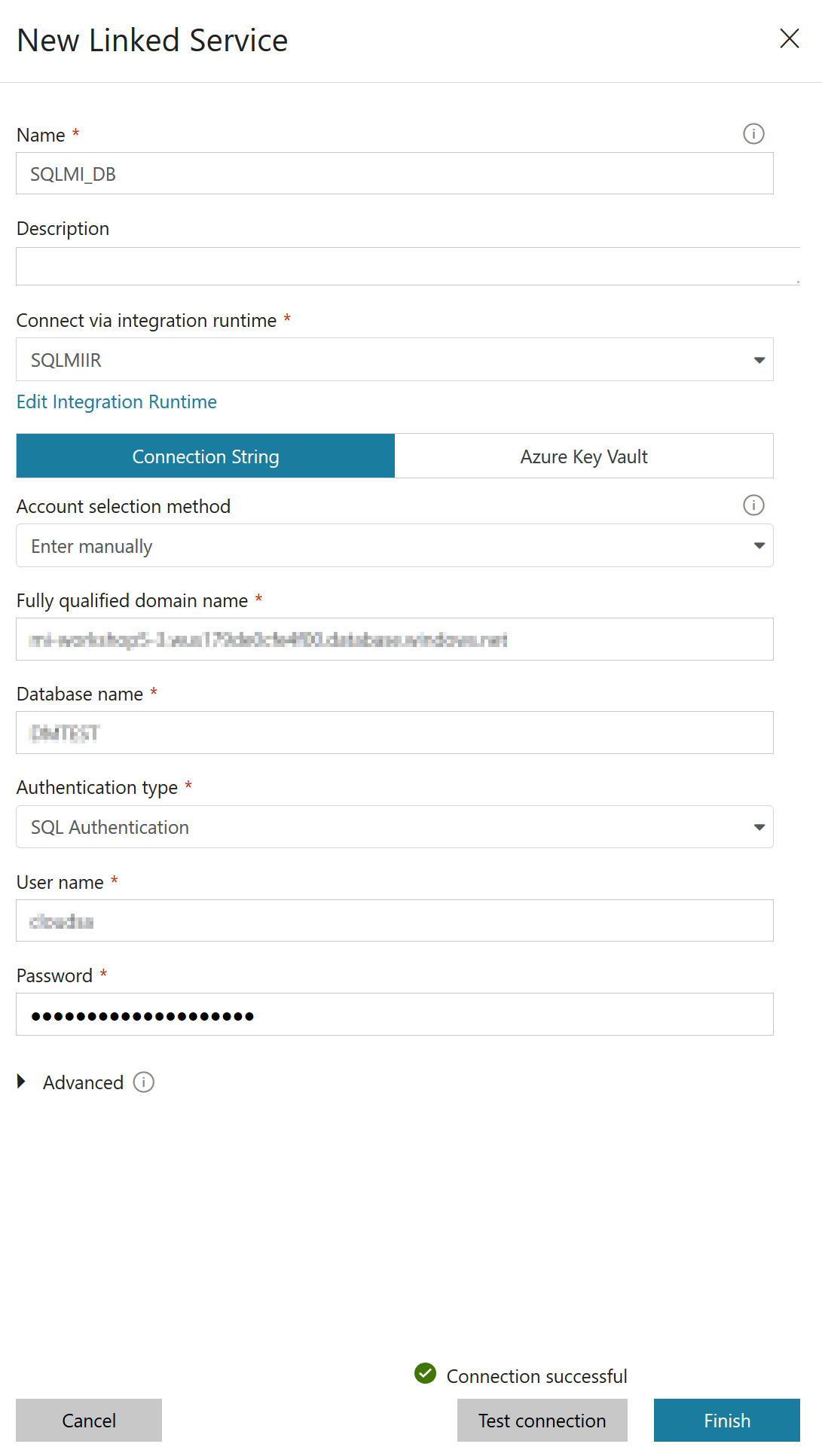
Or, if you’re using the Copy Data Wizard you have to select “VNET in Azure Environment” as value for the “Network Environment” option in order to be able to choose which IR to use:
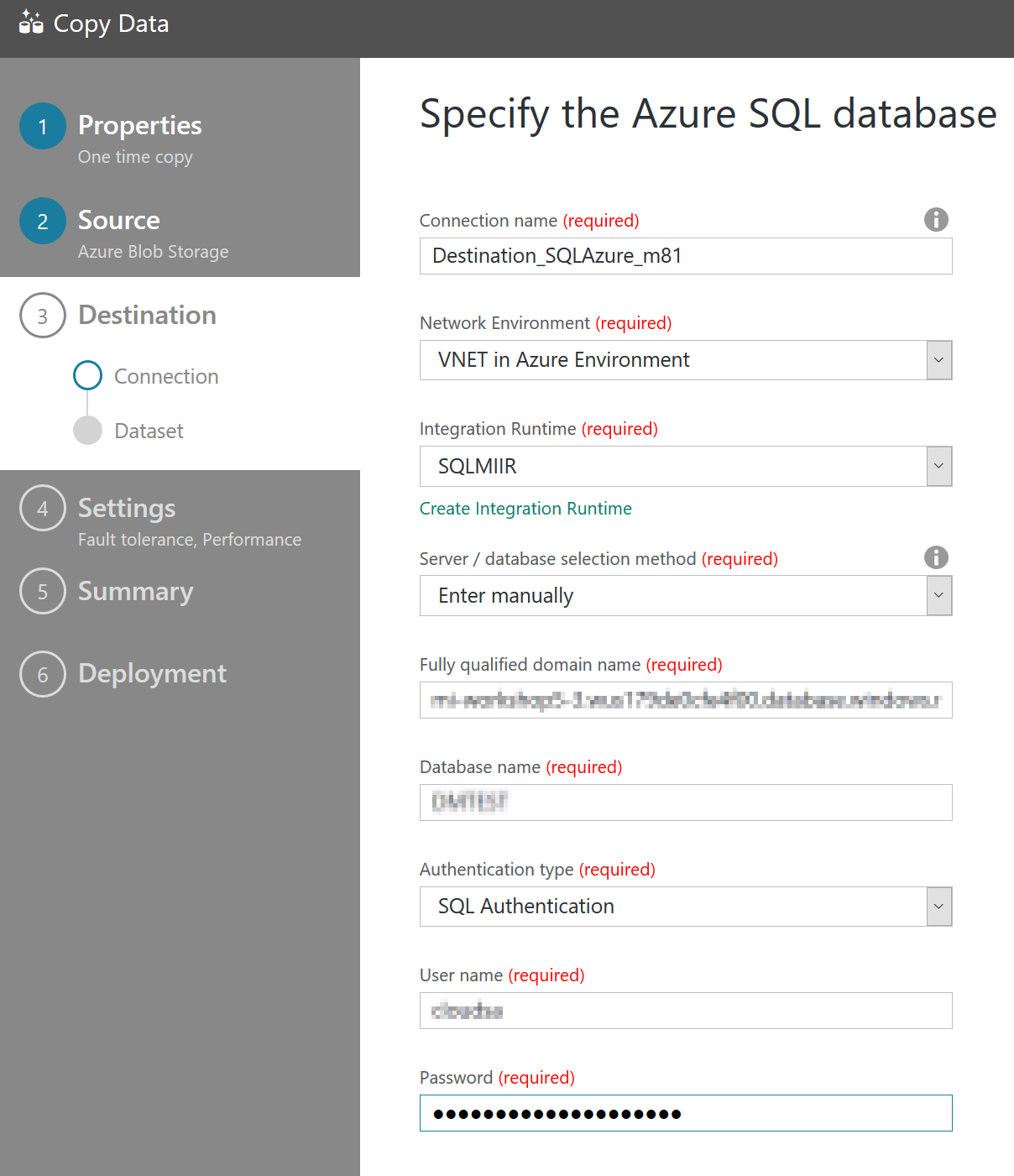
Once this is done, your pipeline will run just fine, moving data from a Blob Store to your database in the SQL MI: